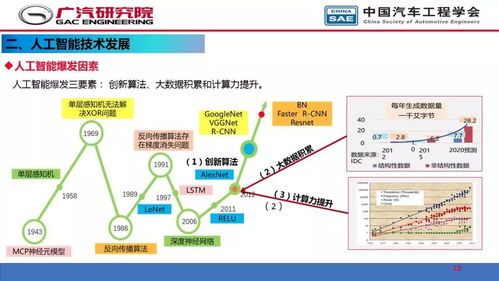
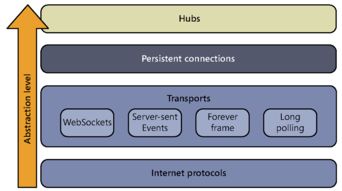
在当今技术飞速发展的时代,人工智能(AI)已从科幻概念转变为驱动各行各业创新的核心引擎。其中,基于大模型的AI软件开发,特别是聊天机器人的构建,正成为连接技术潜力与商业应用的关键桥梁。这不仅是代码的编写,更是一场涉及数据、算法、工程与伦理的综合性实践。
人工智能基础:从理论到代码
一切始于坚实的基础。人工智能基础软件开发要求开发者深入理解机器学习、深度学习的核心原理,如神经网络、梯度下降、自然语言处理(NLP)和计算机视觉(CV)。掌握Python、TensorFlow、PyTorch等主流框架和语言是入门的基石。真正的“基础”远不止于此,它还包括对数据预处理、特征工程和模型评估等实践环节的娴熟运用,这是将数学公式转化为有效代码的第一步。
大模型训练:数据与算力的交响乐
大模型(如GPT、BERT系列)标志着AI能力的质变。其训练是一个极其复杂的过程:
1. 数据海洋:需要收集、清洗、标注海量、高质量、多样化的文本、图像或多模态数据,数据质量直接决定模型上限。
2. 架构设计:基于Transformer等先进架构,设计或选用适合任务的模型结构。
3. 分布式训练:在GPU/TPU集群上,利用并行计算技术(如数据并行、模型并行)应对千亿乃至万亿参数的训练任务,管理巨大的算力消耗与成本。
4. 优化与调参:精细调整学习率、批次大小、优化器等超参数,并运用混合精度训练、梯度裁剪等技术提升训练效率和稳定性。
这一过程如同一场交响乐,需要算法工程师、数据工程师和运维工程师的紧密协作。
大模型部署:让模型“活”起来
训练好的模型必须部署到生产环境才能创造价值。部署阶段面临独特挑战:
- 模型压缩与加速:通过量化、剪枝、知识蒸馏等技术,减少模型体积、降低推理延迟,以适应边缘设备或实时性要求高的场景。
- 服务化与API化:使用如TensorFlow Serving、TorchServe或FastAPI等工具,将模型封装成可远程调用的高性能微服务。
- 可扩展性与高可用:利用容器化(Docker)和编排(Kubernetes)技术,确保服务能够弹性伸缩,应对高并发请求,并保证服务持续可用。
- 监控与维护:建立完善的日志、指标监控和告警系统,持续跟踪模型性能(如响应时间、准确率)和数据分布变化,准备进行模型迭代更新。
聊天机器人开发:AI的“人格化”界面
聊天机器人是当前大模型最直观的应用之一,它将复杂的技术封装成自然、友好的对话界面。开发一个智能聊天机器人需整合多层面技术:
- 核心引擎:基于预训练的大模型(如ChatGPT、文心一言、通义千问的API或开源模型)进行指令微调或提示工程,使其理解用户意图并生成连贯、安全、有用的回复。
- 对话管理:设计对话状态跟踪和业务流程逻辑,处理多轮对话、上下文理解和任务型对话(如订餐、客服)。
- 领域增强:通过检索增强生成技术,接入特定知识库(如企业文档、产品手册),使机器人回答更专业、准确,避免“幻觉”。
- 安全与合规:内置内容过滤、敏感词识别和伦理对齐机制,确保对话内容安全、合规、无偏见。
- 多模态融合:结合语音识别与合成、图像理解,打造能听、会说、能看的全感官交互体验。
未来展望与挑战
AI基础软件、大模型与聊天机器人的开发正朝着更高效、更普惠、更可信的方向演进。低代码/无代码平台在降低开发门槛;开源生态的繁荣加速了创新;对模型可解释性、公平性和隐私保护的关注也日益加深。未来的开发者不仅是编码者,更是AI能力的架构师、伦理的守护者和跨界应用的探索者。
从扎实的AI基础编程,到驾驭庞然大物般的大模型训练与部署,再到打造拟人化、实用化的聊天机器人,这条技术链构成了现代AI软件开发的核心脉络。它要求开发者不断学习,在代码世界与智能前沿之间架起一座坚实而灵活的桥梁。